

As big data growth becomes one of today's key economic and technological challenges, many analysis tools are positioning themselves to provide companies with a deeper understanding of their customers.
Among these tools, automatic language processing tools have been developed to identify the verbatim key feelings of Internet users. These freely produced comments are strategic for brands and represent a veritable goldmine of information to help your reputation. However, the nature of these messages, natural language, differentiates them from the data that companies used to process and brings new analysis constraints.
No tool can offer an exhaustive study of verbatim, despite advances in sentiment analysis research. Therefore, it is worth recalling some fundamental linguistic elements to provide answers to the following question: why is automatic sentiment analysis so complicated?
If certain words alone express a positive (super, good, nice, interesting) or negative (unacceptable, disappointed, angry, shameful) feeling, identifying their presence in a statement is not enough to define the tone of this statement. For example, the verbatim easy-to-use explicitly conveys a feeling of positivity that can be associated with the adjective easy. In contrast, the affirmation not easy to use always includes the adjective easy, but the tone of the statement is shifted by the negation particle not. This simple example highlights one of the limits of the lexical approach and the need to implement a morpho-syntactic approach to take into account the context in the semantic analysis.
Some current techniques make use of lexicometric processing, combining linguistic and statistical analyses. Others rely on machine learning techniques to automatically improve the performance of analytics programs as they are used. Whatever method is used, not all the subtleties of language can be reconstructed in the form of algorithms to be recognized by a computer system. Language is composed of different levels of articulation, each with its challenges:
- Lexical level
- Syntactic level
- Semantic level
- Pragmatic level
This article offers you an overview of these levels and is illustrated with examples.
I. Lexical level
Textual data is subject to particular orthographic forms. Spelling errors, which are frequent in media such as social networks, only complicate the automatic analysis of a text.
 A tweet where the brand 'Under Armour' was misspelled as 'Under Armor'
A tweet where the brand 'Under Armour' was misspelled as 'Under Armor'
The same is true with the various possible spellings generated by the use of SMS language, even abbreviations to respect the 140-character limit on Twitter.
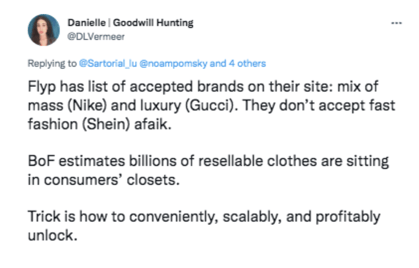 Twitter user using short form for 'as far as I know' as 'afaik'
Twitter user using short form for 'as far as I know' as 'afaik'
Due to this multiplication of orthographic forms, the recognition of lexical units for sentiment analysis is all the more difficult.
II. Syntactic level
Since the information is in the form of free text and natural language, the analyzer may be confronted with heterogeneous syntactic forms, not always meeting the usual grammatical standards. The language used by some Internet users is spontaneous and can sometimes be messy. Words are not always used in their original form when it comes to expressions for example (it's not pie, rain check...). Internet users don’t hesitate to modify the structure of sentences (absence of verbs, incomplete sentences) and sometimes reproduce in writing certain characteristics related to speaking.
 Example
Example
This simplification of use by Internet users make analysis all the more difficult since the "sentences" are not constructed in the same way and do not follow the same rules. As long as the uses of the language are continuously evolving, it would be too complex to recognize a large number of syntactic forms for any sentence structure to be analyzed.
III. Semantic level
The first difficulty relating to semantics is the polysemy of words, which can make any analysis of meaning ambiguous and create misunderstandings. We can take the example of the vague lexical unit whose primary meaning is neutral:
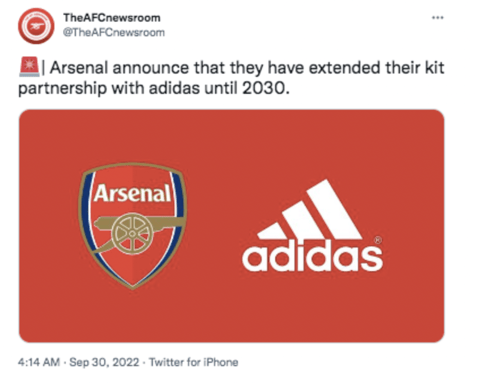
Example
Its tonality is brought to vary when it is used in a different context. In the example below, the mention is very subjective and its tone becomes negative. If any English speaker can tell the difference between the meaning of these two photos, how can a machine measure the nuance between the two?
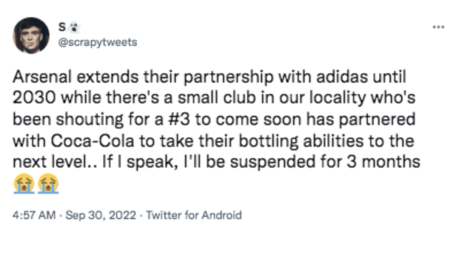
Example
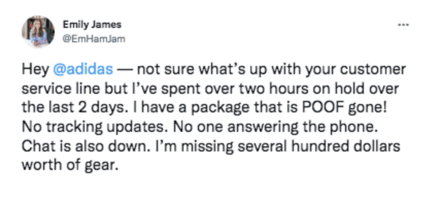
The second difficulty lies in the use of negative forms, usually recognizable by the joint use of the adverb 'ne' and a particle 'pas, none, plus'... In certain uses, the negative form can be reduced to the use of a single particle (not aesthetic). In the following example, the statement is very positive despite the presence of lexical unit problems.
Example
Other semantic phenomena contribute to the complexity of automatic sentiment analysis. It is often a source of error for analysts to find opposition between two propositions, linked by just or yet. Generally, the two propositions have opposing tones.
However, the parsers can assign only one tone (positive, negative, or neutral by default) and cannot make nuances, which makes the semantic analysis lose all its richness. This semantic richness is also undermined with intensity particles, which allow for attenuating or amplifying words. Adverbs of intensity beside subjective keywords can present different degrees of tonality, allowing verbatims to be noted on a scale rather than in a binary way.
IV. Pragmatic level
In order to comprehend a linguistic level, one must understand the situation in general, not just the context imposed by its utterance. Several elements outside the language are often included, including information about the speakers (age, gender, social status), spatial landmarks, and so on.
Concerning the analysis of feelings, the difficulty also lies in the identification of phenomena such as irony, sarcasm, and the implicit. These phenomena are for the majority of cases identifiable by humans. However, an automatic analyzer cannot possess all the contextual knowledge that these types of phenomena require. Note, however, that certain elements can automatically identify these linguistic phenomena, such as the presence of the hashtag #irony in a tweet.

Example
Today, sentiment analysis makes it possible to identify the general tone of a corpus when the opinions of Internet users are explicitly expressed. The article only presents an overview of language phenomena, which can alter the tone of an utterance despite not being taken into account by software.
Language, far from being binary, abounds in a multitude of subtleties that make it rich, subtleties that only a human being can, for the moment, identify. This is why many e-reputation projects today rely on two essential pillars: a powerful social media monitoring tool coupled with the expertise of an analyst.
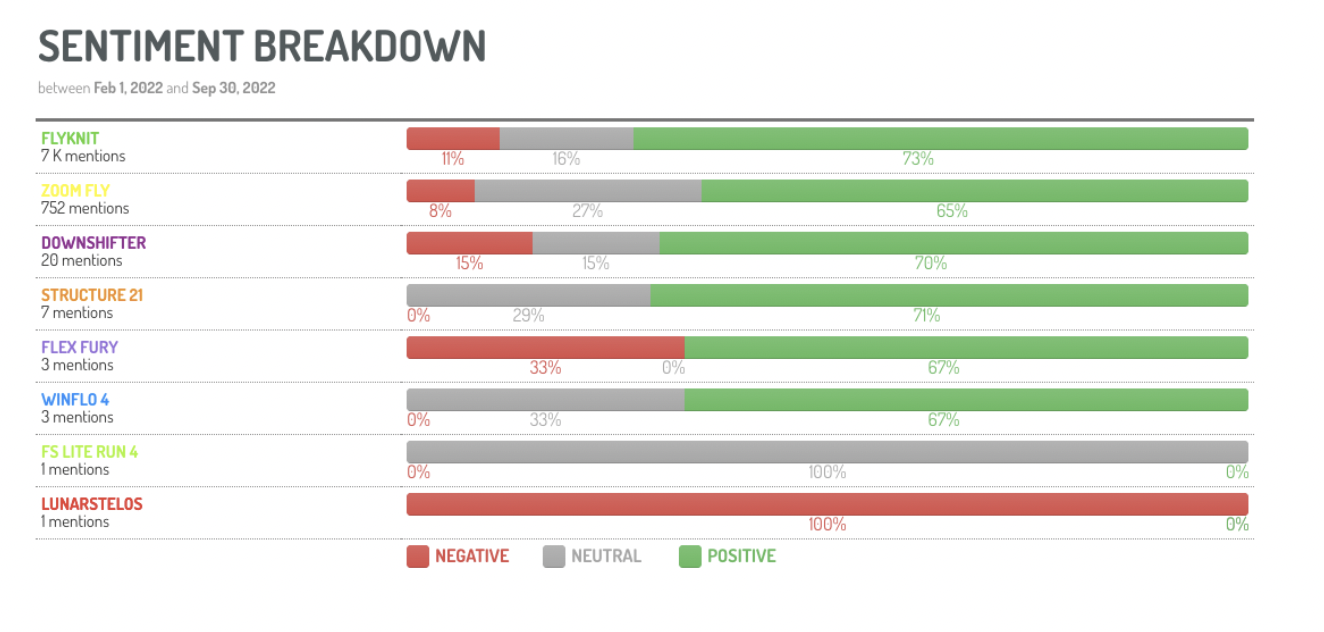 A measure of the overall sentiment expressed about your brand based on positive and negative mentions
A measure of the overall sentiment expressed about your brand based on positive and negative mentions
Besides the sentiment percentage of the volume of conversations as shown in the image above, Digimind's social sentiment analysis offers a variety of metrics. Among them is the Net Sentiment Score, a measure of overall sentiment calculated by taking the difference between positive and negative mentions into account. In addition, Net Sentiment Trend measures the change in net sentiment score over time. It allows analysts to identify the shifts in sentiments over time to better understand consumer loyalty.
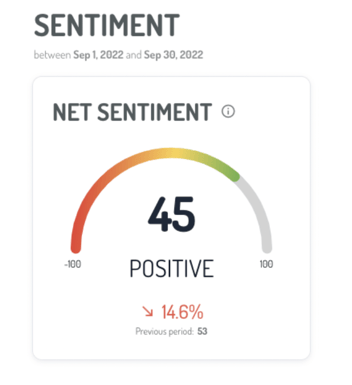 Net Sentiment Score
Net Sentiment Score
 Net Sentiment Trend displays a graph for you to easily identify different peaks of sentiments from a period of time
Net Sentiment Trend displays a graph for you to easily identify different peaks of sentiments from a period of time
The ergonomics of Digimind's Social software allow our analysts to quickly qualify a large number of verbatim statements. This software, designed to facilitate the analysis of large bodies of information, also has an advanced system of rules that allows the information collected to be contextualized. For example, different filters can be combined to change the tone of certain mentions based on criteria specific to a sector of activity, or terms and expressions specific to an event or a period of crisis.
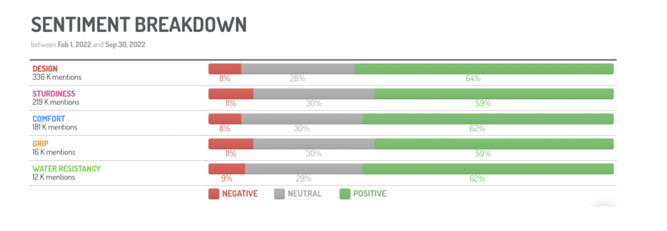
Sentiment mentions specialized towards the shoe attributes mentioned in the previous Sentiment example
