

Le terme Intelligence Artificielle (IA) est devenu un Buzzword, et est souvent employé en lieu et place de bons vieux algorithmes classiques. De fait, cela crée beaucoup de croyances, de mythes liés à ce que l’on pense être l'Intelligence Artificielle, des attentes démesurées, des erreurs sur les domaines où l’IA est réellement utile, et les secteurs où elle ne l’est pas, des incompréhensions sur ses impacts potentiels.
De nombreuses technologies sont utilisées pour rendre les outils de veille et d'écoute des médias sociaux plus performants et "intelligents". A travers des exemples d'Intelligence Artificielle pour le marketing, et plus spécifiquement des applications concrètes dans le domaine du social media, regardons quelles sont les réalités et les vraies dimensions de l’IA dans le monde de l'entreprise. Avec l'aimable contribution de Aurélien Blaha, CMO chez Digimind.
I. Intelligence Artificielle ? Non, Machine Learning
II. Mythes et réalités de l’IA et du Machine Learning
1. Les mythes de l'IA
2. Les 3 niveaux d'Intelligence Artificielle
3. Les 2 niveaux du Machine Learning
III. 3 exemples de Machine learning supervisé en Social Media Listening
1. Le tagging par machine learning (ML)
2. L’analyse de sentiment par Machine Learning
3. Le machine learning pour le visual listening
IV. Le Machine Learning non supervisé (UML)
I. Intelligence Artificielle ? Non, Machine Learning
L'IA décrit le processus d'une machine qui imite certaines fonctions cognitives telles que l'apprentissage et la résolution de problèmes. À un degré plus basique, l'Intelligence Artificielle peut simplement désigner une règle programmée par un humain qui dit à la machine, l'ordinateur de se comporter d'une manière spécifique dans certaines situations.
Ainsi, le vocable d’IA peut désigner le plus élémentaire comme le plus complexe.
Aussi, lorsque nous parlons d'Intelligence Artificielle, il est plus précis de considérer 2 sous-domaines plus spécifiques de l'IA : l'Apprentissage Automatique (Machine Learning) et l'Apprentissage en profondeur (Deep Learning).
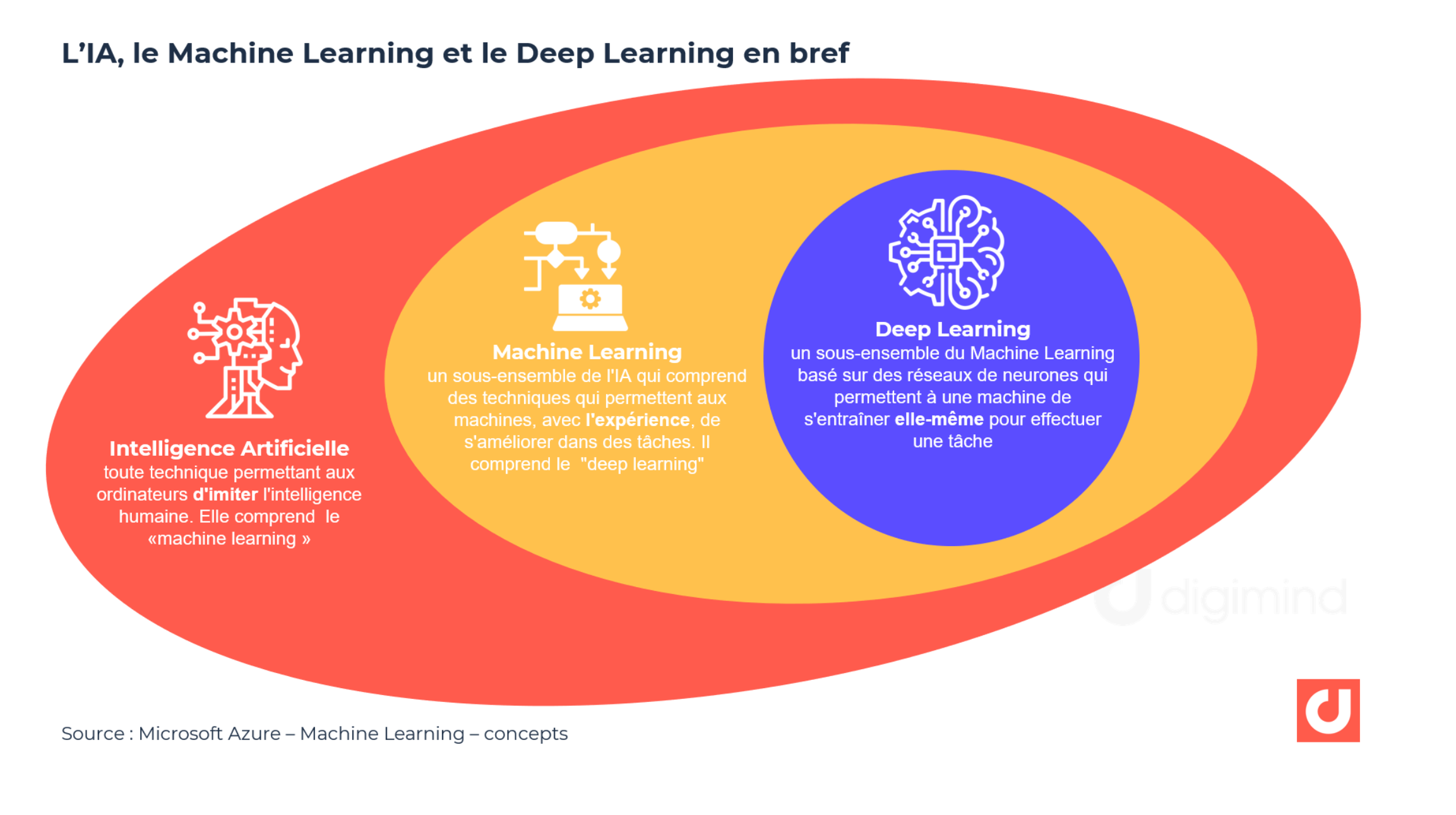 IA vs Machine Learning vs Deep Learning
IA vs Machine Learning vs Deep Learning
Le Machine Learning
Le Machine Learning est donc un sous-ensemble de l'IA. Il fournit les méthodes statistiques et les algorithmes et permet aux ordinateurs d'apprendre “automatiquement” de leurs expériences et données précédentes et permet au programme de modifier son comportement en conséquence. Les séries d'algorithmes de machine learning analysent les données, en tirent des enseignements et prennent des décisions éclairées sur la base de ces connaissances acquises.
Application : Les plateformes de streaming vidéo comme Netflix utilisent le Machine Learning pour recommander des films en fonction des données de visionnage antérieures du client : il s'améliore constamment en apprenant des statistiques des expériences passées.
Le deep learning
Contrairement au machine learning, le Deep Learning est un sous-domaine récent de l'intelligence artificielle basé sur les réseaux de neurones artificiels.
Les algorithmes de Deep Learning nécessitent également des données pour apprendre et résoudre des problèmes, aussi, on peut le considérer comme un sous-domaine du Machine Learning. Les termes Machine Learning et Deep Learning sont souvent traités comme des synonymes. Cependant, ces systèmes ont des capacités différentes. L'apprentissage en profondeur utilise une structure multicouche d'algorithmes appelée réseau de neurones.
Les réseaux de neurones artificiels ont des capacités uniques qui permettent aux modèles de Deep Learning de résoudre des tâches que les modèles d'apprentissage automatique ne pourraient jamais résoudre. Le Deep Learning est alors utilisé pour résoudre des problèmes complexes où les données sont vastes, diversifiées, moins structurées. Il apprend progressivement des données brutes et des expériences précédentes et se corrige sans programmation explicite et préalable comme pour le ML.
Applications : certaines reconnaissances faciales, les algorithmes de pilotage des voitures autonomes, les assistants virtuels comme Alexa, Siri, les chirurgies robotiques.
II. Mythes et réalités de l’IA et du Machine Learning
1. Les mythes de l'IA
Pour démystifier l’IA et ses croyances, revenons sur 2 citations de vrais spécialistes et praticiens de l'Intelligence Artificielle :
Yann Le Cun, Chief AI scientist, Facebook Research Division explique : "L’Intelligence artificielle n'est même pas au niveau d'un cerveau de rat"
Et Luc Julia, Directeur Scientifique Renault, précédemment Director of AI Research Samsung, et l’un des pères de Siri : "Ce que l’on appelle intelligence artificielle depuis 1956 ce sont des techniques mathématiques qui n’ont rien à voir avec l’intelligence. Il n’en reste pas moins que ces techniques (deep learning, machine learning, etc.) sont très intéressantes. Mais la machine ne crée pas, ne réfléchit pas, et les humains conservent pleinement la main sur ces techniques."
Luc Julia est d’ailleurs l’auteur de l’ouvrage “L'intelligence artificielle n'existe pas”. A lire...
Exemple de Mythes :
- L'IA est nouvelle dans le marketing.
En fait, les spécialistes du marketing ont construit de nombreuses fondations opérationnelles de l’IA. Ainsi Forrester montre dès 2016, dans son enquête Global State Of Artificial Intelligence Online Survey que les départements Marketing / Ventes sont les premiers à mener les investissements et l'adoption des systèmes d’IA dans l'entreprise.
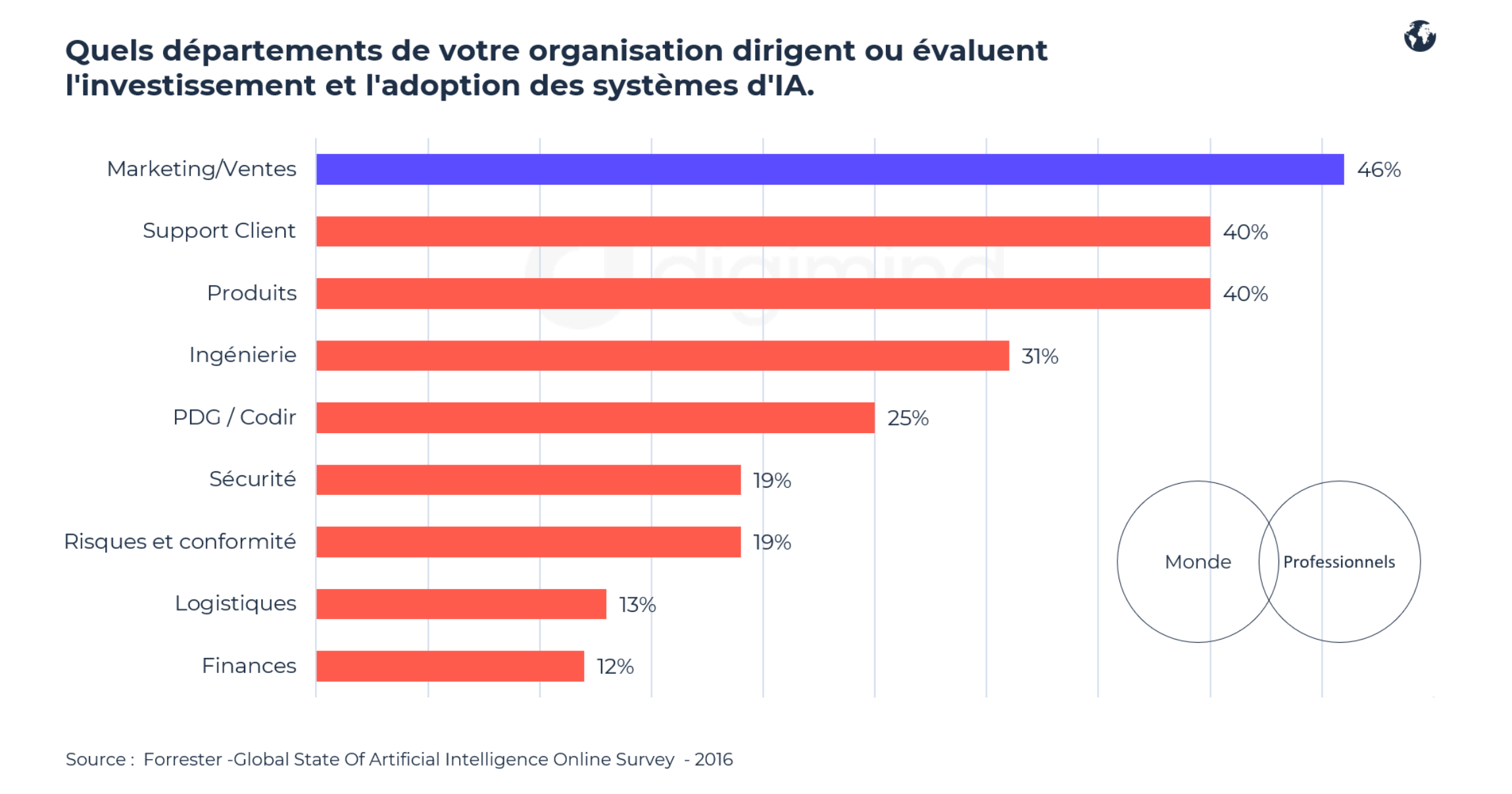 Forrester - Global State Of Artificial Intelligence Online Survey
Forrester - Global State Of Artificial Intelligence Online Survey
- L'IA c’est avant tout de "super" algorithmes
En réalité, cela concerne davantage les data. Si vous avez de superbes algorithmes mais pas ou trop peu de données pour apprendre et tester, cela ne fonctionnera pas. Mais plutôt que de parler de Big data, mieux vaut évoquer des Smart Data, des ensembles de données pertinentes pour le Machine learning par exemple.
- L'IA mettra les spécialistes du marketing au chômage.
En fait, l'IA permet avant tout aux professionnels du marketing de faire leur vrai travail. De se concentrer sur les tâches à haute VA et délaisser les tâches fastidieuses et répétitives à la machine.
2. Les 3 niveaux d'Intelligence Artificielle
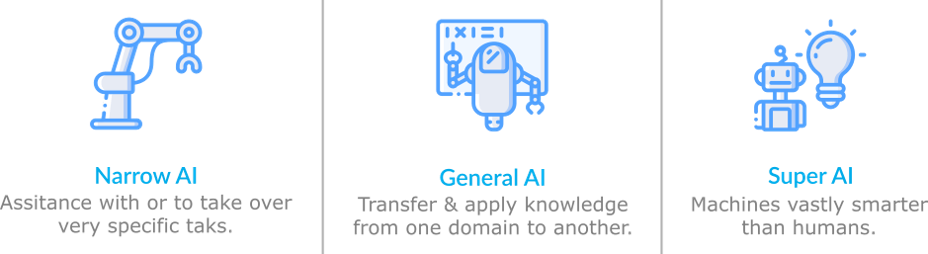
Aujourd’hui, l’IA dont on parle est la “Narrow AI” : Les systèmes d'IA étroite sont conçus et entraînés pour accomplir une tâche spécifique et sont souvent appelés aussi "IA faible". Ex: Les chatbots qui répondent aux questions en fonction des entrées des utilisateurs, les assistants vocaux comme Siri, la reconnaissances des images prises par votre téléphone qui les trie en fonction du sujet : portraits, animaux, paysages, selfies,...
L'IA générale (strong AI) : quand les systèmes d'IA fonctionneront à égalité avec un autre humain. Cela signifie la capacité de la machine à interpréter et à comprendre le ton et les émotions humaines et à agir en conséquence. Elle transfère et applique la connaissance et l'apprentissage d’un domaine à un autre domaine pour une autre application : reconnaître les images des chiens pour ensuite reconnaître les chiens dans la vie courante.
La Super AI : très prospectif : Quand une machine intelligente prendrait conscience d'elle-même et surpasserait l'intelligence et les capacités humaines. Cela implique de pouvoir répondre à n'importe quelle question en cumulant notamment la Narrow AI et la General AI , répondre comme le fait le cerveau humain : savoir connecter des choses qui n'ont pas forcément de corrélation entre elles.
3. Les 2 niveaux du Machine Learning
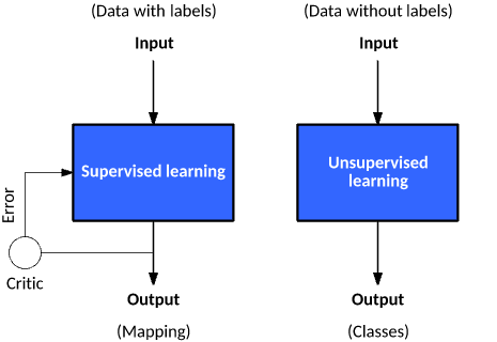
Machine Learning supervisé et Machine Learning non supervisé - Source : AI Wiki
Pour l’apprentissage automatique, il faut distinguer le Machine Learning Supervisé (SML) et le Machine Learning non supervisé (UML).
Le Machine Learning supervisé (SML)
On dit à la machine quoi rechercher, la cible et le type de donnée. Ex : en entrée, on lui fournit des images de chien et de chat étiquetées : on lui indique les bonnes réponses c’est à dire le type d’animal sur chaque photo : un chat ou un chien. La machine pourra identifier alors ensuite ces images similaires dans la bonne catégorie et en apprendre d’autres.
Chez Facebook, Yann Le Cun consacre l'essentiel de ses travaux de recherche à l'apprentissage auto-supervisé.
Le Machine Learning non supervisé (UML)
Ici, on nourrit la machine avec des data, mais on n'est pas sûr de ce que l’on va trouver comme résultats. On ne fournit donc pas “d’étiquettes”. Ex: on collecte un large volume de données, et la machine devra trouver si il y a des corrélations entre certaines de ces données pour en faire des classes et donc des groupes.
Un algorithme peut apprendre de manière non supervisée, par exemple, en faisant une estimation de la distribution des données sur la base d'un échantillon, puis en vérifiant sa supposition par rapport à la distribution réelle. Ce que l'on apprend généralement, en l'absence d'étiquettes, c'est comment reconstruire les données d'entrée à l'aide d'une représentation.
Dans le traitement en langage naturel (TAL/NLP), utiliser des mots pour prédire leurs contextes, avec des algorithmes comme word2vec, est une forme d'apprentissage non supervisé.
Le social listening propulsé à l'Intelligence Artificielle

III. 3 exemples de Machine learning supervisé en Social Media Listening
Le Social Media Listening désigne les processus, démarches et outils consistant à “écouter” et analyser les messages, articles et conversations des médias et internautes postés sur les médias sociaux afin de nourrir les tactiques et stratégies, pour le marketing notamment, mais pas seulement.
Le cadre va bien au-delà des réseaux sociaux (type Facebook, Twitter, Pinterest ou Instagram), puisque l’on parle bien de Social Media, à savoir les médias sociaux, c'est-à-dire tous les espaces du web hébergeant des articles, messages et conversations. Voici quelques exemples de Machine Learning utilisés par les meilleurs outils de Social Listening.
On va regarder maitenant un extrait d'applications du Machine Learning au social listening, utiles pour le Community Manager et le Social Media Manager
1. Le tagging par machine learning (ML)
Une des fonctions d’analyse des outils de social media listening est le “tagging”, l'étiquetage c’est à dire la qualification et classfication des messages et articles collectés : Un message d’un consommateur disant “ce médicament du laboratoire BioSysH pour le cœur est efficace. Quelques effets secondaires de jambes lourdes mais c’est tout” pourra être ainsi "taggé" avec les étiquettes Santé, Pharma, laboratoire, BiosysH, effets indésirables, médicaments, cardiologie etc..
a. Le Machine learning pour le taggage va s’avérer très pertinent, dès la construction de vos requêtes de surveillance de tout ce que l’on dit sur vous, vos produits, vos marques et dirigeants sur le web et les médias sociaux.
Imaginons que vous deviez surveiller tout ce que l’on dit sur la Fnac :
Si vous utilisez une requête booléenne classique (opérateurs booléens AND NOT OR…), cela va donner ce type d’expression : FNAC OR #FNAC OR @Fnac. C’est simple. Il n’y a pas d’ambiguïté, le mot Fnac n’a pas d’autre signification dans le langage courant.
Imaginons maintenant que vous deviez surveiller tout ce qui se dit en anglais sur la chaîne de magasins, Target, cinquième entreprise de grande distribution aux États-Unis, derrière Wal-Mart, Home Depot, Kroger et Costco.
Le travail se complique puisque "Target" est aussi un verbe et un nom commun très courants. Votre requête booléenne va devoir exclure toutes les expressions “target” qui ne correspondent pas aux magasins, avec des risques de manquer des messages intéressants. Sur l’illustration ci-dessous, on voit la longueur après les opérateurs AND NOT de tous les mots à exclure.

J’aurais pu prendre aussi l’exemple classique de Orange : on veut surveiller l’opérateur Telecom. On va devoir exclure des centaines d’expressions comme “fruit” “ville d’Orange”, "festival d’Orange" avec des requêtes de type NOT (jus OR “jus d’orange” OR fruit? OR juice OR couleur OR color OR "revolution orange" OR "agent orange" OR "orange mecanique" OR "alerte orange" OR “orange is the new black" OR "orange idot") etc....
C’est là que le Machine Learning montre sa puissance et son efficacité et permet un gain de temps élevé, en vous évitant l’écriture fastidieuse de requêtes, leur mise à jour puis le nettoyage de résultats non pertinents.
Il suffit juste de commencer par la simple requête “Orange”.
Puis le ML va apprendre à l'algorithme de surveillance les mentions pertinentes pour Target ou Orange dans le cadre de votre veille. Cela, à l’aide d’une interface qui va vous proposer un lot de mentions contenant le mot “Orange” ou "Target", mentions qu'il faudra indiquer comme pertinentes ou non. Dans un second temps, l’interface de Machine Learning va vous proposer un échantillon de résultats dont il faudra valider la pertinence (image ci-dessous).
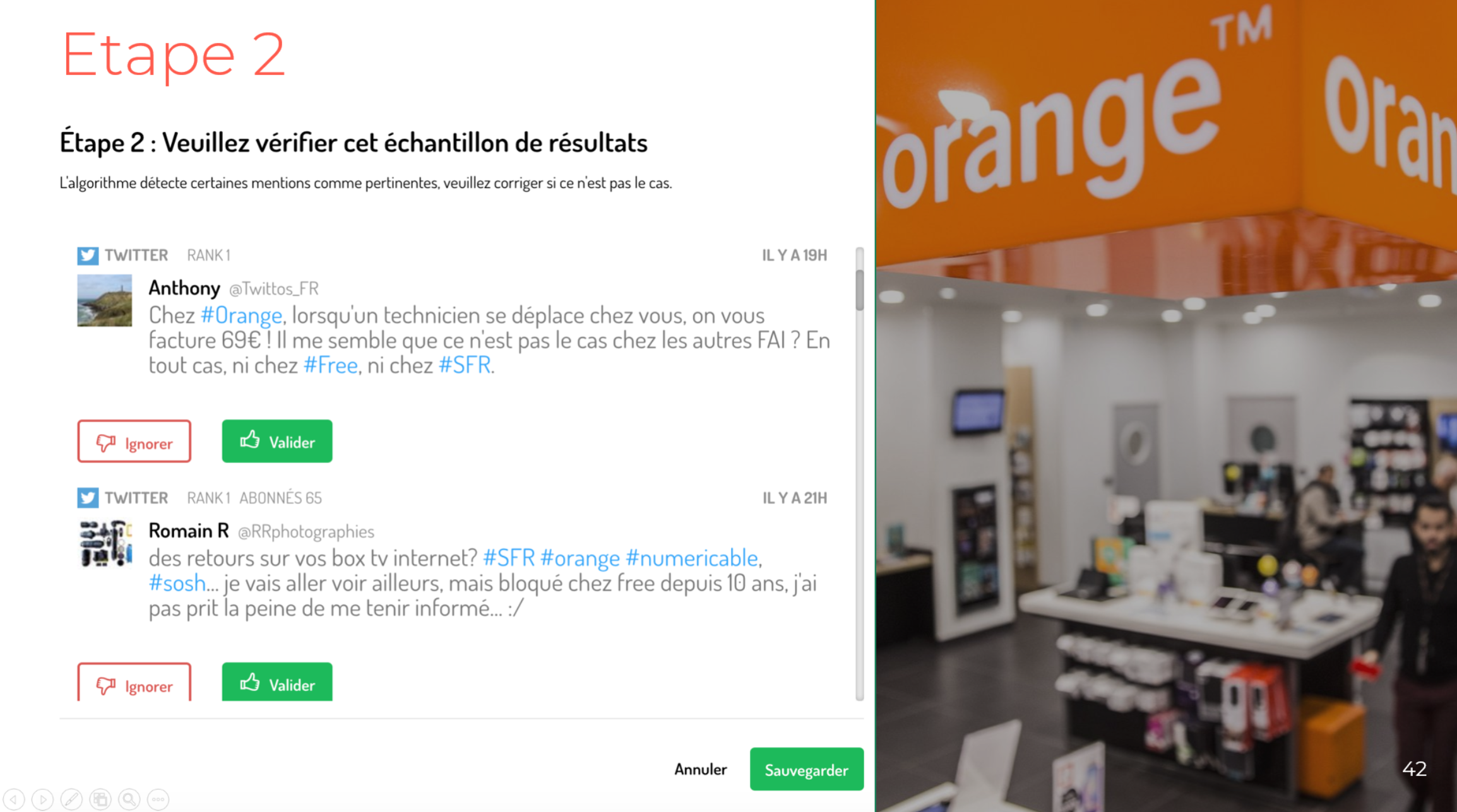 Etape de vérification d'un échantillon de résultats fournis par le machine learning
Etape de vérification d'un échantillon de résultats fournis par le machine learning
En moyenne, une vingtaine d'occurrences permettent de parvenir à un taux de précision de taggage de 95%. Bien entendu, le système de ML va apprendre au fur et à mesure des futurs taggages de mentions.
b. Par extension, le tagging par Machine Learning permet la classification intelligente de toutes les mentions collectées : Après une phase d'apprentissage avec l'utilisateur, l'apprentissage automatique combiné avec le NLP permet de comprendre la nature des mentions associées à chaque tag (étiquette) et de tagger automatiquement toutes les mentions collectées, pour une organisation rapide et pertinente des données.
2. L’analyse de sentiment par Machine Learning
L’analyse de sentiment est un process d’analyse des outils de veille et de social listening consistant à étiqueter une mention, un message, un article selon le sentiment dominant qui y est exprimé : négatif, positif, neutre, mitigé.
Avant le Machine Learning, on utilisait le NLP seul (Natural language processing - Traitement automatique du langage) : en simplifiant, la phrase est en quelque sorte analysée en morceaux, et les expressions sont alors qualifiées en négatif ou positif. D'où une limitation de la pertinence et la présence de silence (des sentiments non qualifiés) quand :
- Le message comporte à la fois du négatif et du positif, la mention est qualifiée alors en type ‘inconnu”. Le cynisme, l’ironie, si fréquente dans notre langue sont quasiment impossibles à détecter
- Le message est trop court ou mal structuré pour permettre une bonne analyse via NLP.
Les éditeurs de logiciels de social listening évoquent une pertinence de l'analyse de sentiments automatique qui varie alors entre 40% et 75% selon que l’on est en présence, au mieux d’un article de presse structuré, au pire d’un court tweet en langage familier.
En combinant le NLP au Machine Learning, le “silence”, à savoir les mentions non qualifiées en sentiment est très fortement réduit.
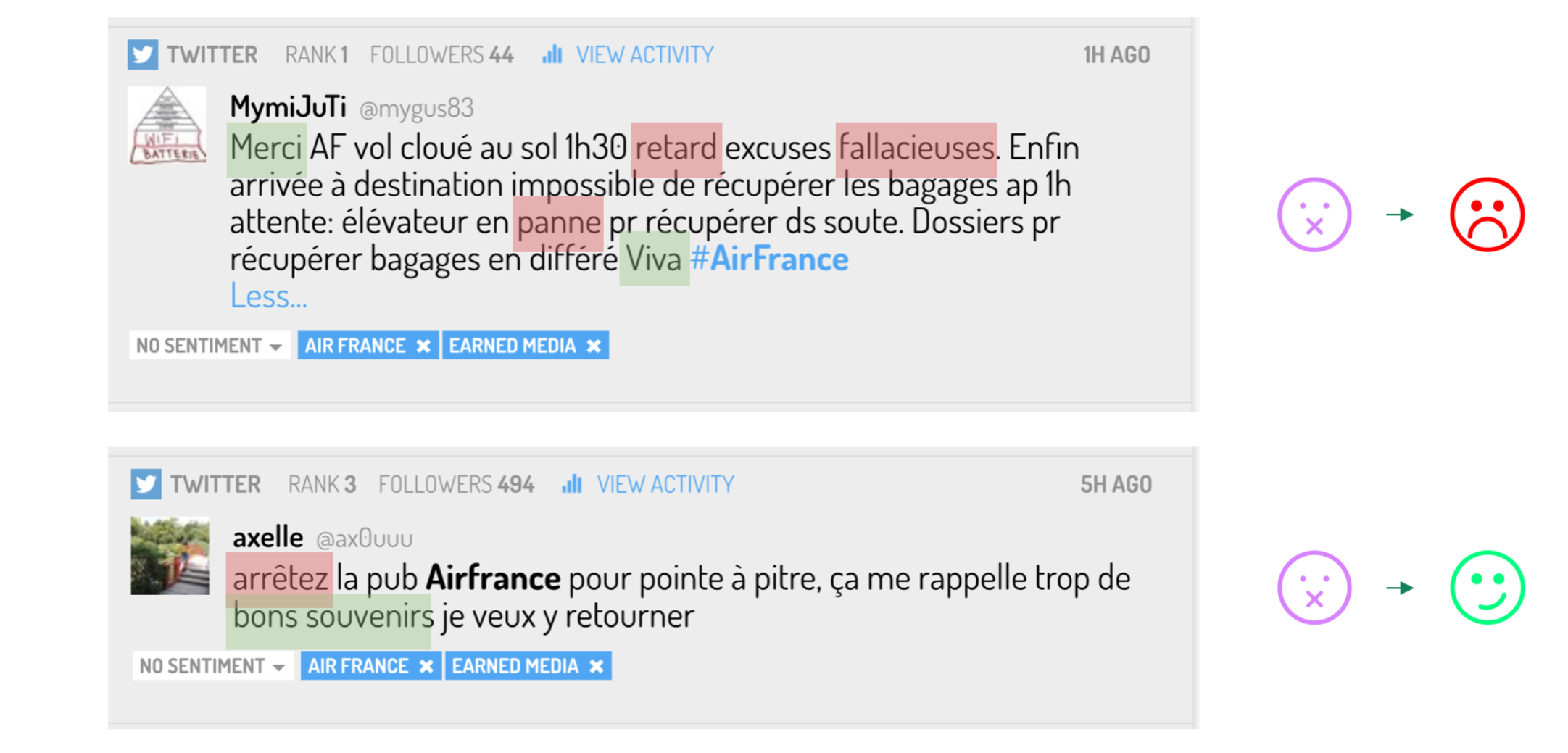 L’analyse de sentiment optimisée par Machine Learning
L’analyse de sentiment optimisée par Machine Learning
Comme pour le taggage, l'interface d’apprentissage de Machine learning sera nourrie par vos exemples et saura dire que le message 1 est négatif (plutôt que “non qualifié”) et le message 2 est positif malgré le mot “arrêtez”.
3. Le deep learning pour le visual listening
Prenons le cas maintenant du visual listening à savoir la surveillance d’entités (noms, logos) à l'intérieur des images.
En approche classique, via des requêtes basées sur le texte, vous surveillez les messages comportant les noms de votre marque. Exemple pour le nom d’un vin californien : Josh Cellars" OR "#betterwithjosh" OR BetterWithJosh OR joshcellars OR "#joshcellars" OR "@joshcellars"
Or, avec un post Instagram comme celui ci-dessous, aucune mention écrite de la marque ne figure dans le message accompagnant la photo.
Ici, le Deep learning, par apprentissage de reconnaissance de la marque dans l’image de l’étiquette, permet d'identifier puis de qualifier ce message en “positif”.
 La reconnaissance d'images par DeepLearning permet d'identifier la marque, absente du texte mais présente dans l'image.
La reconnaissance d'images par DeepLearning permet d'identifier la marque, absente du texte mais présente dans l'image.
La reconnaissance d’images par Deep Learning offre de nombreuses applications en veille :
- reconnaissance de simples logos s'affichant seuls sans mention de la marque (exemple : le Woosh, l’aile de Nike, le crocodile Lacoste, le “C” de Carrefour, la coquille de Shell).
- reconnaissance d'environnement (mer, montagne, ville)
- reconnaissance de genre etc…
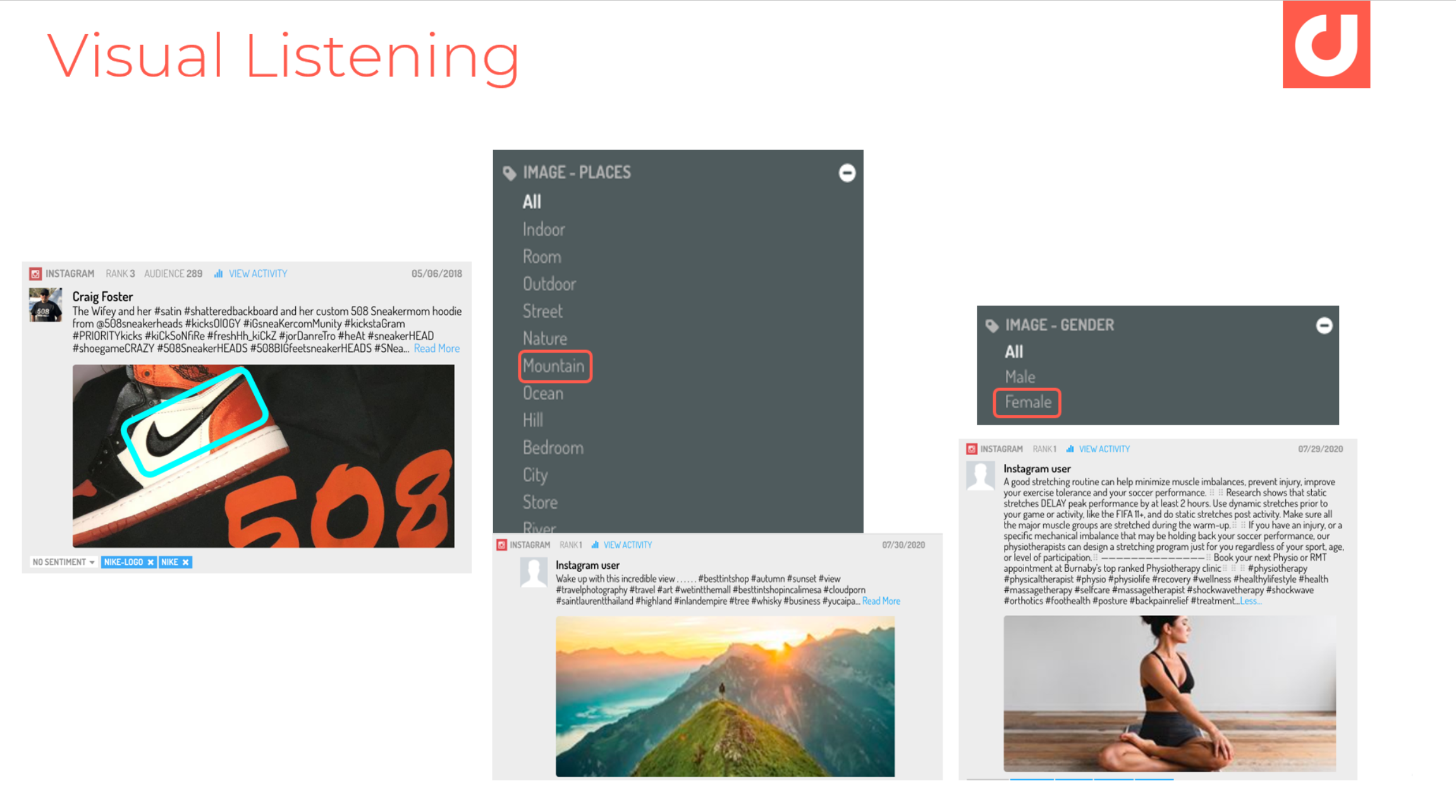 Les applications du visual listening par Deep Learning
Les applications du visual listening par Deep Learning
IV. Le Machine Learning non supervisé (UML)
Rappelons qu'ici on “nourrit” la machine avec des data, mais on ne lui fournit pas d’étiquettes pour catégoriser des données : Elle va plutôt estimer la distribution des données sur la base d'un échantillon.
Exemple d’application : pour votre métier, vous avez besoin d'analyser, d’identifier voir d'anticiper des tendances à partir de la collecte de centaines voire de milliers de messages sur le web et les médias sociaux. Vous devez identifier les événements qui impactent votre sujet, comprendre rapidement l'évolution d'un marché, d'une entreprise.
Si vous travaillez en analyse manuelle, vous devez explorer chaque évolution significative sur votre courbe de données (augmentation, baisse, pic) afin de comprendre l'événement présent (Crise, résultats financiers, levée de fond) et imaginer ensuite l’évolution potentielle.
C’est très chronophage surtout si vous devez analyser plusieurs marchés ou entreprises. Vous devez en effet cliquer sur de nombreux points des courbes afin de lire l’information correspondante.
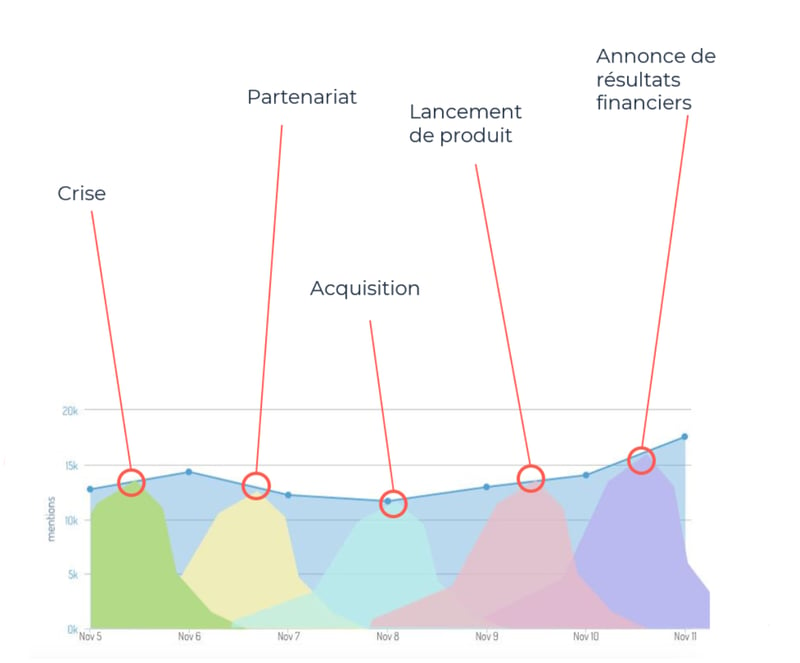 Identification automatique des événements par Machine Learning
Identification automatique des événements par Machine Learning
Le Machine Learning non supervisé (UML) permet d‘identifier automatiquement la nature d’une évolution de tendances et de dire par exemple si un pic correspond plutôt à une marque, un produit, si la variation est habituelle ou inhabituelle, si l'événement concerne un lancement de produit, un rachat, une nomination.
En bref, l’UML permet de détecter automatiquement des corrélations entre un certain nombre d'informations collectées sur le web et d'en déduire des tendances, là où un travail à la main nécessite des heures de lecture. La machine effectue cette analyse sans que l’humain ai eu besoin de qualifier préalablement des données types, l’UML identifie automatiquement les événements des variations. Elle permettra de jeter les bases d'une analyse prédictive.
Ce ne sont que quelques-unes des applications possibles du Machine Learning aux algorithmes des outils de veille et de social listening...
Le social listening propulsé à l'Intelligence Artificielle

Sources
- Analytics Vidhya : AI vs ML vs DL
- Builtin : AI vs ML
- Microsoft Azure - Machine Learning
- Forrester’s Q2 2016 Global State Of Artificial Intelligence Online Survey
- Forrester : “AI Must Learn The Basics Before It Can Transform Marketing”
- AI Wiki supervised-learning, unsupervised-learning
- Digimind Academy