

A l’heure où le big data représente l’un des grands défis technologiques et économiques actuels, de nombreux outils d’analyse se positionnent sur le marché afin d’offrir aux entreprises une connaissance clients davantage poussée.
Parmi ces outils, ceux spécialisés dans le traitement automatique du langage, et en particulier l’analyse de sentiments, se sont développés afin d’identifier rapidement les sentiments clés issus de verbatim d’internautes. Ces commentaires produits librement sont stratégiques pour les marques et représentent une véritable mine d’or d’informations.
Toutefois, la nature de ces messages, du langage naturel, les différencie des données que les entreprises avaient l’habitude de traiter et apporte de nouvelles contraintes d’analyse.
Force est de constater que malgré l’avancée de la recherche dans le domaine de l’analyse de sentiments, aucun outil ne propose une étude exhaustive de verbatim. Dès lors, il convient de rappeler quelques éléments linguistiques fondamentaux pour apporter des réponses à la question suivante : pourquoi l’analyse automatique de sentiments est-elle si compliquée ?
Si certains mots expriment à eux seuls un sentiment positif (super, bien, sympa, intéressant) ou négatif (inacceptable, déçu, énervé, honteux), identifier leur présence dans un énoncé ne suffit pas à définir la tonalité de cet énoncé. Par exemple, le verbatim facile d’utilisation exprime bien un sentiment positif identifiable par l’adjectif facile. En revanche, l’affirmation pas facile d’utilisation comporte toujours l’adjectif facile mais la tonalité de l’énoncé est inversée par la présence de la particule de négation pas. Ce simple exemple met en avant une des limites de l’approche lexicale et la nécessité de mettre en place une approche morpho-syntaxique afin de tenir compte du contexte dans l’analyse sémantique.
Certaines techniques actuelles font appel à des traitements lexicométriques, mêlant analyses linguistiques et statistiques. D’autres s’appuient sur des techniques d’apprentissage automatique afin d’améliorer automatiquement les performances des programmes d’analyse au fur et à mesure de leur utilisation.
Quelle que soit la méthode utilisée, toutes les subtilités du langage ne peuvent être reconstituées sous forme d’algorithmes pour être reconnues par un système informatique. En effet, la langue comprend différents niveaux d’articulation, chaque niveau comportant son lot de difficultés :
- Niveau lexical
- Niveau syntaxique
- Niveau sémantique
- Niveau pragmatique
Cet article vous propose un tour d'horizon de ces niveaux, illustrés bien-sûr d’exemples.
1. Niveau lexical
Les données textuelles sont soumises à des formes orthographiques particulières. Les fautes d’orthographe, fréquentes dans les médias de type forums ou réseaux sociaux, ne font que compliquer l’analyse automatique d’un texte.
Il en est de même avec les diverses formes orthographiques possibles que génère l’utilisation du langage SMS ou encore les abréviations afin de respecter la limite des 140 caractères sur Twitter.
Y'a que moi qui arrive pu ouvrir fb ak mon iPhone ?
— MB (@baralocca) 15 Juillet 2014
De par cette multiplication des formes orthographiques, la reconnaissance des unités lexicales pour l’analyse de sentiments n’en est que plus difficile.
2. Niveau syntaxique
L’information étant sous forme de texte libre et donc en langage naturel, l’analyseur peut être confronté à des formes syntaxiques hétérogènes, ne répondant pas toujours aux normes grammaticales habituelles. Le langage utilisé par certains internautes est spontané et peut parfois être désordonné. Les mots ne sont pas toujours employés dans leur forme originale, lorsqu’il s’agit par exemple d’expressions (c’est pas de la tarte, raconter des salades…). Les internautes n’hésitent pas à modifier la structure des phrases (absence de verbes, phrases incomplètes) et reproduisent parfois à l’écrit certaines caractéristiques liées à l’oral.
@JordanJosii hum je sais pas quoi faire, pff mon iphone commence trop à déconner :/ — ❤️Deep ❤️ (@DeepigaOfficial) 16 Juillet 2014
Cette simplification d’emploi par les internautes rend l’analyse d’autant plus difficile puisque les « phrases » ne sont pas toutes construites de la même manière et ne répondent pas toutes aux mêmes règles. Pour pouvoir analyser n’importe quelle structure de phrase, il faudrait alors prévoir la reconnaissance d’une multitude de formes syntaxiques, ce qui serait trop complexe sachant que les usages de la langue évoluent sans cesse.
3. Niveau sémantique
La première difficulté relative à la sémantique est la polysémie des mots, qui peut rendre ambiguë toute analyse du sens et créer des incompréhensions. Nous pouvons prendre l’exemple de l’unité lexicale vague dont le sens premier est neutre :
[post] Soyez averti de la prochaine vague de précommandes du smartphone Jolla http://t.co/Qu4DB0ELq6
— JollaFr (@JollaFr) 23 Août 2013
Sa tonalité est amenée à varier lorsqu’elle est utilisée dans un contexte différent.
Dans l’exemple ci-dessous, la mention est bien subjective et sa tonalité devient négative. Si n’importe quel locuteur français peut faire la différence entre le sens de ces deux emplois, comment une machine peut-elle prendre mesure de la nuance entre les deux ?

La seconde difficulté réside dans l’utilisation de formes négatives, habituellement reconnaissables par l’utilisation conjointe de l’adverbe ne et d’une particule pas, aucun, plus... Dans certains emplois, la forme négative peut être réduite à l’utilisation d’une seule particule (pas esthétique). Dans l’exemple suivant, le propos est bien positif malgré la présence de l’unité lexicale problèmes.
#RT Je vend un iPhone 5 de 16 GO débloqué avec sa boîte d'origine. Il n'a aucun problème juste quelques éraflures pic.twitter.com/kpPILvx8A4 — . (@MoktarSunni) 14 Juillet 2014
D’autres phénomènes sémantiques contribuent à complexifier l’analyse automatique des sentiments. L’opposition entre deux propositions, unies par mais ou pourtant, est souvent source d’erreur pour les analyseurs. Dans la majorité des cas, les deux propositions ont des tonalités opposées.
Top 10 de smartphones, l’iPhone 5S numéro 1 mais Samsung domine http://t.co/lDiLuMuylU — Le Blogueur Libre ن (@LeBlogueurLibre) 15 Juillet 2014
 Cependant, les analyseurs ne peuvent attribuer qu’une seule tonalité (positive, négative ou neutre par défaut) et ne peuvent faire de nuances, ce qui fait perdre à l’analyse sémantique toute sa richesse. Cette richesse sémantique est également mise à mal avec les particules d’intensité, qui permettent d’atténuer ou d’amplifier des propos. Dans le cas où des adverbes d’intensité sont présents à proximité de mots-clés subjectifs, la tonalité pourrait présenter différents degrés et permettre ainsi de noter les verbatims sur une échelle, et non plus de façon binaire (positif vs négatif) comme c’est le cas actuellement.
Cependant, les analyseurs ne peuvent attribuer qu’une seule tonalité (positive, négative ou neutre par défaut) et ne peuvent faire de nuances, ce qui fait perdre à l’analyse sémantique toute sa richesse. Cette richesse sémantique est également mise à mal avec les particules d’intensité, qui permettent d’atténuer ou d’amplifier des propos. Dans le cas où des adverbes d’intensité sont présents à proximité de mots-clés subjectifs, la tonalité pourrait présenter différents degrés et permettre ainsi de noter les verbatims sur une échelle, et non plus de façon binaire (positif vs négatif) comme c’est le cas actuellement.
#iPhone6 : Un #smartphone très attendu dans les #Apple Store http://t.co/owG2shrQUY — Infos Mobiles (@infos_mobiles) 16 Juillet 2014
Le conditionnel est également source de confusion et peut changer complètement la tonalité d’un verbatim, comme dans l’exemple ci-dessous :
Par l’utilisation du conditionnel, l’internaute exprime ici une attente et rend la tonalité du propos négative, alors que le verbe apprécier exprime intrinsèquement un sentiment positif.
4. Niveau pragmatique
Ce niveau linguistique implique une connaissance générale du contexte de la situation, et pas seulement du contexte induit par l’énoncé lui-même. Cela englobe souvent des éléments extérieurs au langage, à savoir différentes informations sur les locuteurs (âge, sexe, statut social), des repères spatio-temporels…
Pour ce qui est de l’analyse de sentiments, la difficulté réside également dans l’identification de phénomènes tels que l’ironie, le sarcasme, l’implicite. Ces phénomènes sont pour la majorité des cas identifiables par les hommes. Cependant, un analyseur automatique ne peut posséder toute la connaissance contextuelle que requièrent ces types de phénomènes.
Notons toutefois que certains éléments peuvent permettre d’identifier automatiquement ces phénomènes langagiers, comme la présence d’un hashtag #ironie dans un tweet.
Beaucoup de monde à l'ouverture du #Samsung Store aujourd'hui, à quelques minutes de la place de l'Opéra... #Ironie pic.twitter.com/0Xqu7NQd
— Ma'r'cintosh (@Mlg2M) 1 Décembre 2012
Aujourd’hui, l’analyse de sentiments permet d’identifier la tonalité générale d’un corpus lorsque les opinions des internautes sont exprimées explicitement. Cependant, tous les phénomènes langagiers, dont cet article ne présente qu’un aperçu, ne sont pas pris en compte par les logiciels et peuvent pourtant faire varier la tonalité d’un énoncé.
Le langage, loin d’être binaire, regorge d’une multitude de subtilités qui en font sa richesse, subtilités que seul un être humain peut, pour l’instant, identifier. C’est pourquoi de nombreux projets e-réputation s’appuient aujourd’hui sur deux piliers essentiels : un outil de social media monitoring performant couplé à l’expertise d’un analyste.
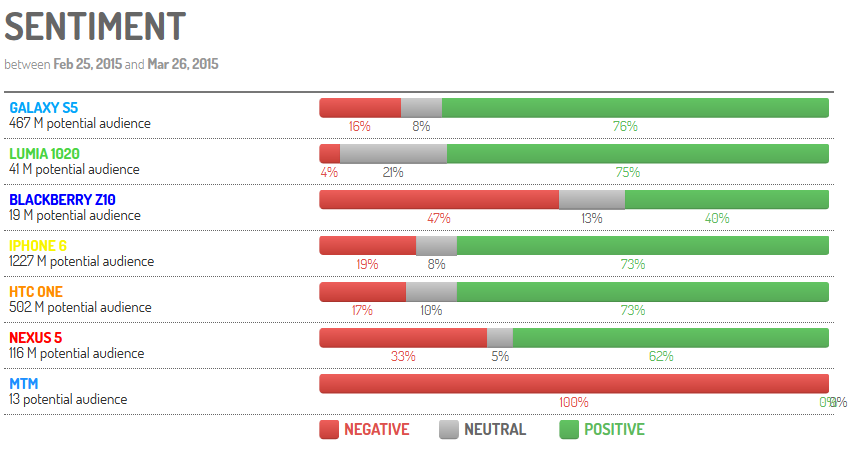
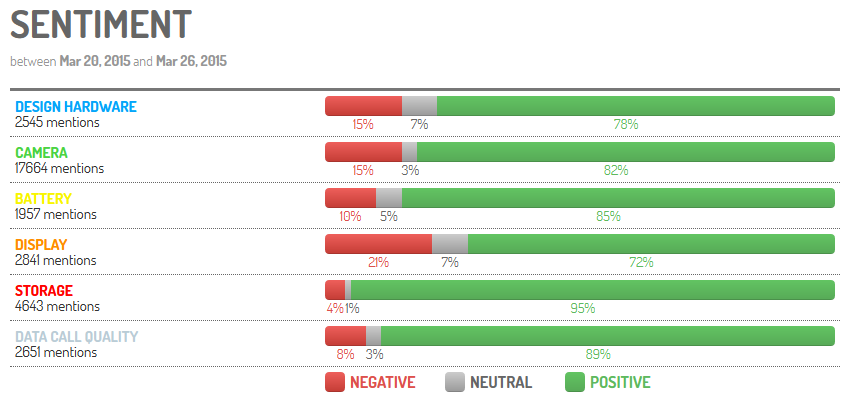
Chez Digimind, nos analystes s’appuient sur le logiciel Digimind Social dont l’ergonomie permet de qualifier rapidement un très grand nombre de verbatim. Ce logiciel conçu pour faciliter l’analyse de gros corpus d’informations dispose également d’un système poussé de règles qui permet de contextualiser les informations recueillies. Par exemple, différents filtres peuvent être combinés afin de changer la tonalité de certaines mentions en se basant sur des critères propres à un secteur d’activité, ou des termes et expressions spécifiques à un événement ou à une période de crise.
Suivez-nous via nos actualités, sur Facebook, Slideshare et Twitter !![]()
![]()
![]()
![]()
